AI 모델을 이용한 Korean-Singing Voice Conversion (Style-Transfer)
개요
내가 좋아하는 가수의 목소리로 다른 가수들의 노래를 듣고 싶다!
프로젝트 과정
- Dataset - Opensource package
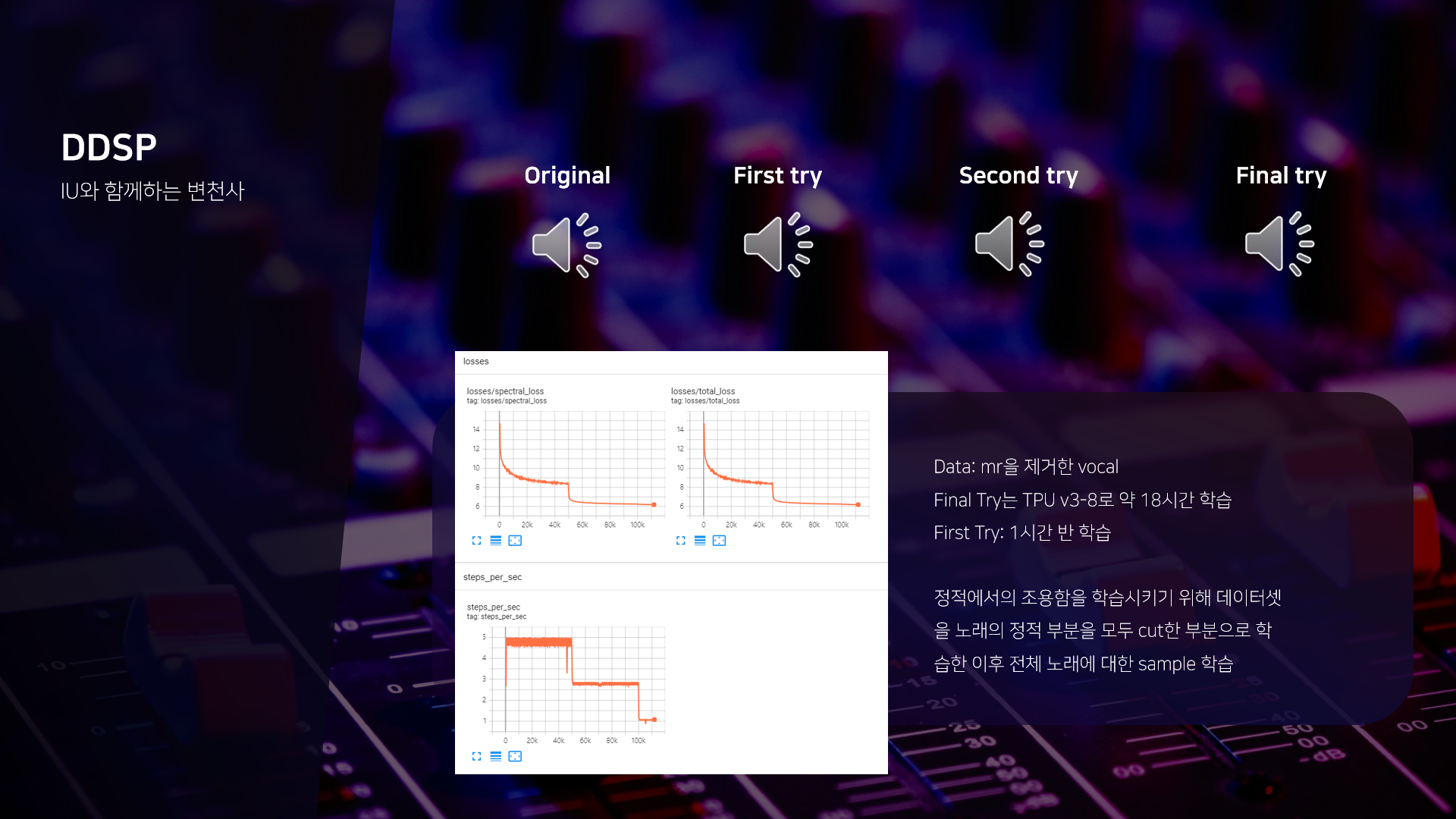
- 모델 Training을 위해 필요한 vocal, MR file은 youtube-dl opensource를 이용.
- 그 외 melodia package를 통해 audio-to-midi model 구축.
- 각 가수 당 50곡 정도의 dataset을 준비
- 모델 준비 및 결과 오디오 파일 생성, Demo 비교
- 위 과정을 통해 준비한 dataset을 통해 MLP를 이용한 MLP-Singer Model, MIR-SVC Model, DDSP module-based Model inference를 통한 Demo를 비교
- 모델 채택 (Structure)과 결과 오디오 파일 생성
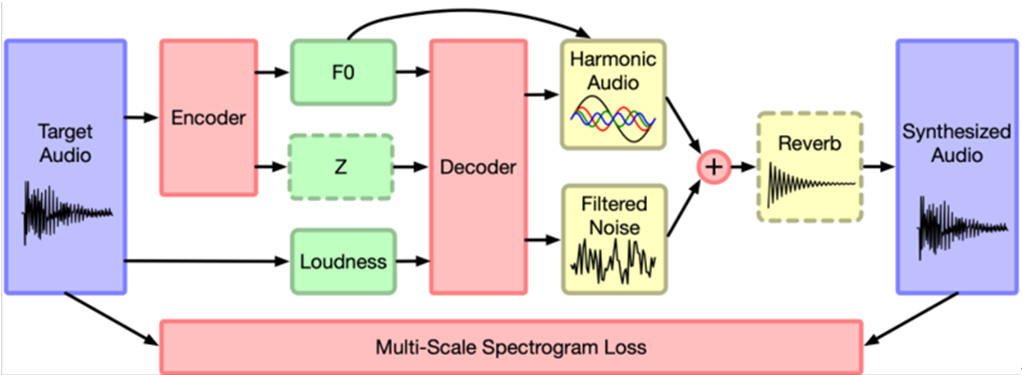
- DDSP module based autoencoder structure를 채택하였으며, structure gin file에 각 audio mel-spectogram의 **fft size를 더욱 세분화하여 loss configuration을 변형하거나, parameter를 조정하여 feature latent space를 확장**하는 등의 여러 변형을 가해 실험